Le présent billet a pour but d’apporter quelques précisions sur le format de retour de l’API, sujet qui vous pose régulièrement question.
La situation actuelle
Actuellement, l’API renvoie les résultats au format JSON sous la forme d’une liste de documents. Chacun d’entre eux est accompagné par un ensemble de métadonnées :
- identifiants (ISSN, DOI…)
- langue du texte
- liste de mots-clés
- résumé
- etc
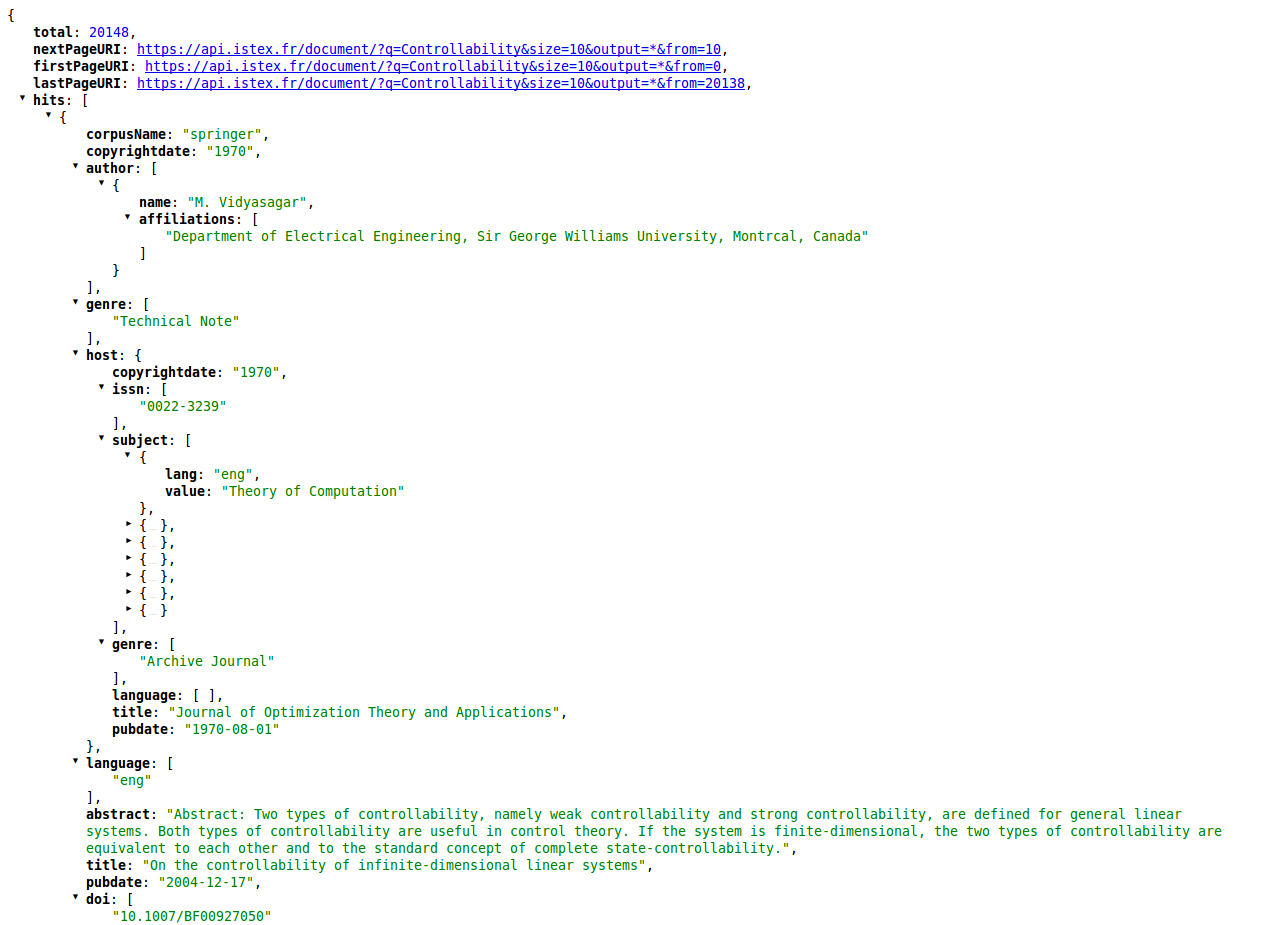
Ces métadonnées ne sont absolument pas complètes. Pour récupérer la totalité d’entre elles, il est nécessaire de consulter la version Mods ou TEI de chaque document trouvé.
Le pourquoi du comment
L’explication est directement liée à la manière dont nous utilisons Elasticsearch, notre moteur de recherche.
Pour rendre l’ensemble des documents cherchables, il est nécessaire de les indexer dans le moteur de recherche en spécifiant un mapping. Ce mapping décrit le plus finement possible quels sont les champs indexés et de quel type ils sont.
L’indexation proprement dite ne se fait pas à partir du fichier d’origine (XML, PDF…) mais dans un format JSON correspondant au mapping précédemment défini.
On passe donc par une étape de conversion Mods vers JSON avant indexation. Celle-ci ne reprend pas l’ensemble des métadonnées contenues dans le fichier Mods, mais seulement une liste prédéfinie.
Et pour l’interrogation ?
Il est important de noter que la structuration même des index impacte fortement la manière de rechercher via l’API.
En effet, lors d’une requête
https://api.istex.fr/document/?q=<requete>
la syntaxe à utiliser pour le paramètre <requete> nécessite de connaître précisément le mapping.
Par exemple, pour trouver des articles dans une revue dont l’ISSN est 0022-3239, il faut utiliser la syntaxe
<requete>=host.issn:"0022-3239"
Une idée d’évolution
Pour permettre la recherche de toutes les métadonnées disponibles et par conséquent leur accès direct via l’API, nous proposons de changer prochainement le mapping / la structuration des index.
L’idée serait de convertir automatiquement l’ensemble des métadonnées (soit MODS, soit TEI) en JSON en suivant une spécification de formatage standard telle que JSONML ou Google Data.
Voilà par exemple à quoi ressemblerait un notice Mods transformée en Json selon la spécification Google Data :
{ mods:
{ xmlns: 'http://www.loc.gov/mods/v3',
'xmlns$xsi': 'http://www.w3.org/2001/XMLSchema-instance',
'xsi$schemaLocation': 'http://www.loc.gov/mods/v3 file://D:/istex/home/etc/xsd/mods.xsd',
version: '3.4',
titleInfo:
{ lang: 'eng',
title: { '$t': 'The manual of cultivated orchid species' },
subTitle: { '$t': 'Revised Edition. By Helmut Bechtel, Phillip Cribb, and Edmund Launert. The MIT Press, 28 Carleton St., Cambridge, MA 02142. ISBN 0-262-02253-2. 1986. 444 pp. $75 (cloth)' } },
name:
{ type: 'personal',
namePart:
[ { type: 'given', '$t': 'James L.' },
{ type: 'family', '$t': 'Luteyn' } ],
affiliation: { '$t': 'New York Botanical Garden, New York, USA' },
role: { roleTerm: { type: 'text', '$t': 'author' } } },
typeOfResource: { '$t': 'text' },
genre: { '$t': 'Book Review' },
originInfo:
{ place: { placeTerm: { type: 'text', '$t': 'New York' } },
publisher: { '$t': 'Springer-Verlag' },
dateValid: { encoding: 'w3cdtf', '$t': '2008-05-30' },
copyrightDate: { encoding: 'w3cdtf', '$t': '1987' } },
language: { languageTerm: { type: 'code', authority: 'iso639-2b', '$t': 'eng' } },
physicalDescription: { internetMediaType: { '$t': 'text/html' } },
relatedItem:
{ type: 'series',
titleInfo:
[ { title: { '$t': 'Brittonia' } },
{ type: 'abbreviated', title: { '$t': 'Brittonia' } } ],
genre: { '$t': 'Archive Journal' },
originInfo:
{ dateIssued: { encoding: 'w3cdtf', '$t': '1987-04-01' },
copyrightDate: { encoding: 'w3cdtf', '$t': '1987' } },
subject:
{ usage: 'primary',
genre: { '$t': 'Life Sciences' },
topic:
[ { '$t': 'Plant Sciences' },
{ '$t': 'Plant Systematics/Taxonomy/Biogeography' },
{ '$t': 'Plant Anatomy/Development' },
{ '$t': 'Plant Physiology' },
{ '$t': 'Plant Ecology' } ] },
identifier:
[ { type: 'ISSN', '$t': '0007-196X' },
{ type: 'ISSN', '$t': 'Electronic: 1938-436X' },
{ type: 'matrixNumber', '$t': '12228' },
{ type: 'local', '$t': 'IssueArticleCount: 43' },
{ type: 'istex',
'$t': '9EEEF43776FB6AEF3F0CA2FACC5A25F5F0FA62E2' } ]
[...]
Une telle modification impacterait donc fortement l’interrogation, car cela impliquerait une bonne connaissance de deux formats :
- le format Mods ou TEI
- la représentation Json « JsonML » ou « Google Data »
Par exemple, une recherche sur les mots du titre s’écrirait :
https://api.istex.fr/document/?q=mods.titleInfo.title.$t:"Controllability"
À vous la parole
Si vous avez des remarques ou des idées, ou encore si vous avez une préférence concernant l’un des formats énoncés, n’hésitez pas à nous en faire part dans les commentaires.

Besoin d'aide ?
Consultez notre Faq, la documentation Istex ou nos tutoriels
N’hésitez pas à nous contacter si besoin, nous reviendrons rapidement vers vous !
Écrivez-nous

Erreur : Formulaire de contact non trouvé !
Bonjour,
Les retours que nous avons reçu de techniciens ayant des problématiques similaires aux nôtres ne nous ont pas permis de trancher en faveur de tel ou tel format, c’est pourquoi nous vous demandons votre avis. Si vous le souhaitez, nous pouvons faire un sondage Google.
Merci à ceux qui prendront le temps de lire ce billet et de répondre à notre question 🙂
Bonjour,
Une telle modification n’impacterais pas que l’interrogation, mais aussi le traitement des réponses, non ?
Je n’ai pas d’avis très éclairé sur l’un ou l’autre des formats,
par contre j’ai un avis très inquiet en tant qu’utilisateur de l’API pour ma BU :
Nous nous apprêtons a mettre en production une nouvelle version de notre catalogue qui intègre l’API ISTEX (version 2.1.2 donc). C’est prévu pour le 22 mai, mais avec si possible, arrêt des modifications au 28 avril.
La mise en place de ce nouveau format, si il apporte indéniablement un plus en terme de métadonnées, change pas mal de chose dans les scripts.
Si l’on ne peut pas rester sur une version connue (donc antérieure) de l’API en attendant de s’adapter à la nouvelle, cela signifie une mise hors service direct de la nouvelle fonctionnalité dans le catalogue.
C’est déjà dommageable en soit, mais si cela devait intervenir peu après sa mise en production, ce serait un suicide ! 🙂
Donc sans répondre à votre question, mais à cause d’un tel changement, j’espère qu’avant celui-ci vous aurez pu mettre en place un mécanisme permettant d’avoir toujours accès à la version n-1 ou n-2 de l’API.
Cordialement
Bonjour,
Effectivement, il va de soi que si nous optons pour un tel changement, un mécanisme d’accès à la version n-1 sera indispensable pour laisser aux utilisateur d’adapter leurs scripts.
Pour l’instant rien n’est fait, mais rassurez-vous, nous communiquerons plus largement en temps voulu et laisserons le temps aux utilisateurs de basculer vers la nouvelle version.
Cordialement
(re)Bonjour,
Juste une réflexion sur le format Google Data.
Je ne suis pas développeur, et pour vous la remarque est peut être naïve,
mais j’ai tout de même commis une ou deux lignes de code
et j’avoue que le $t dans le format et dans la requête
me font craindre quelques petites complexités d’écriture :
soit quand un script php (ou autre) devra écrire du code incluant ce $t,
soit quand il faudra traiter les données avec du jquery par exemple.
Mais je ne serais mesurer si les avantages d’une telle syntaxe l’emporte sur ces éventuelles inconvénients …
Cordialement
Pour ma part, vis à vis du format GData, je me demande comment gérer les champs multi-valués qui dans certains cas ne contiennent qu’une seule valeur.
En effet sur l’exemple, nous avons ceci :
namePart:
[ { type: ‘given’, ‘$t’: ‘James L.’ },
{ type: ‘family’, ‘$t’: ‘Luteyn’ } ],
affiliation: { ‘$t’: ‘New York Botanical Garden, New York, USA’ },
Dans le cas où on a deux affiliations, on aurait alors ceci :
namePart:
[ { type: ‘given’, ‘$t’: ‘James L.’ },
{ type: ‘family’, ‘$t’: ‘Luteyn’ } ],
affiliation: [ { ‘$t’: ‘New York Botanical Garden, New York, USA’ },
{ ‘$t’: ‘CNRS’ } ],
Au niveau programmatique : que ce soit pour indexer la structure au niveau ElasticSearch ou pour l’utilisateur final souhaitant interroger l’API, ça me semble un point relativement gênant car il faut alors tester si jamais le type vaut Array ou bien Object avant de pouvoir le parcourir.