A partir du fonds documentaire ISTEX (https://www.istex.fr/) différents jeux de documents ou de données ont été constitués à partir d’informations extraites automatiquement (entités nommées, catégories scientifiques, etc.) ou bien à partir des informations induites et produites par les documentalistes (types de documents, regroupement des langues, etc.).
Chaque jeux de données est constitué d’un ensemble de ressources. Ces dernières ont fait l’objet d’un enrichissement suivi d’une modélisation (figure 1) en utilisant principalement le vocabulaire SKOS et d’autres propriétés idoines afin de constituer l’ontologie (https://data.istex.fr/ontology/istex/).
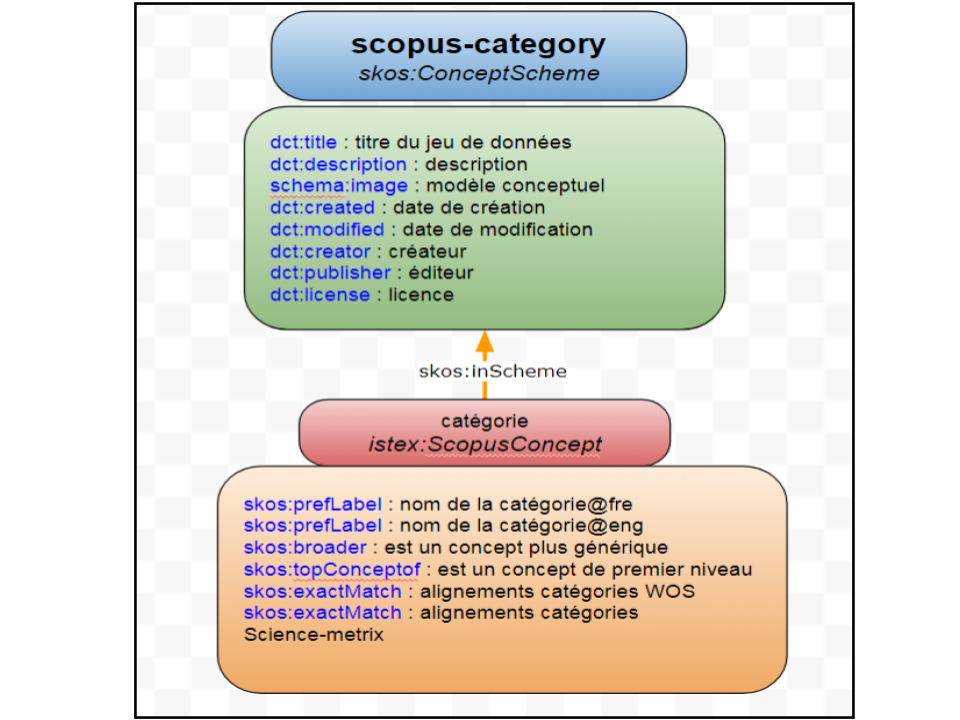
figure 1 : exemple de modélisation d’un jeu de données
L’ensemble des jeux de données constituent data.istex (https://data.istex.fr/) :
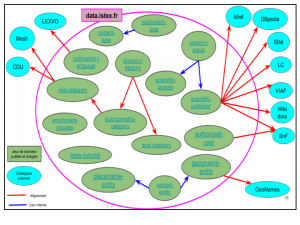
Des alignements manuels entre concepts issus de classifications/thésaurus ou plus généralement des ressources externes ont été réalisés en utilisant la propriété skos:exactMatch (matérialisé par les flèches rouges).
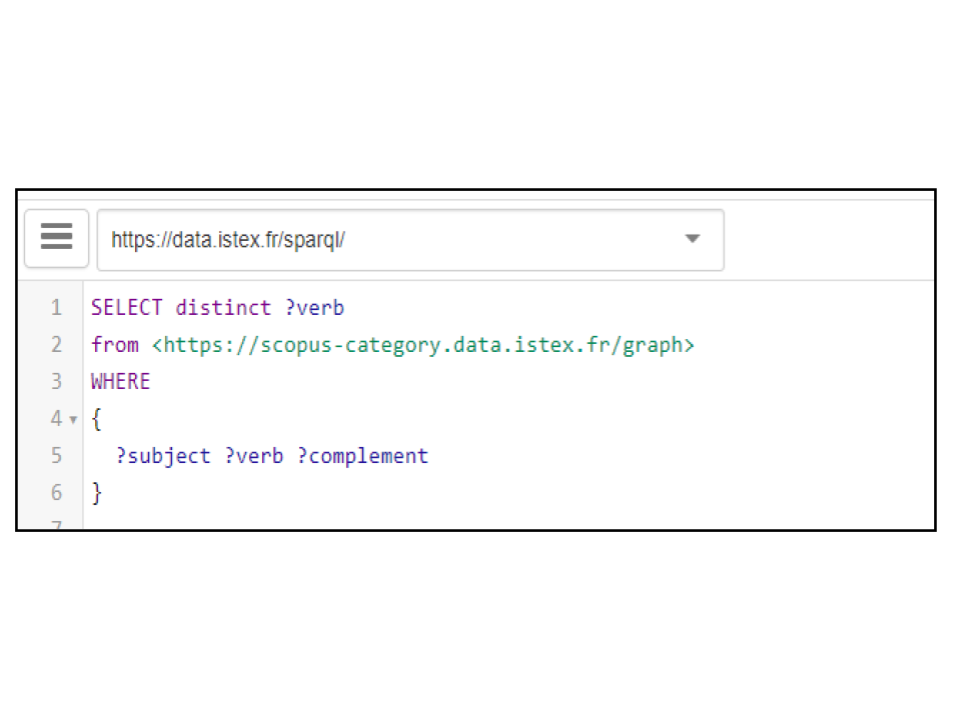
L’ensemble des jeux de données ont été transformés en des graphes nommés dédiés au format N-quads afin d’alimenter notre SPARQL endpoint (https://data.istex.fr/triplestore/sparql). Pour illustrer notre propos, pour connaître toutes les propriétés utilisées pour qualifier un jeu de données ou plus précisément un graphe nommé en langage RDF (par exemple scopus-category), la requête suivante est effectuée :
En retour, nous obtenons les 14 propriétés :
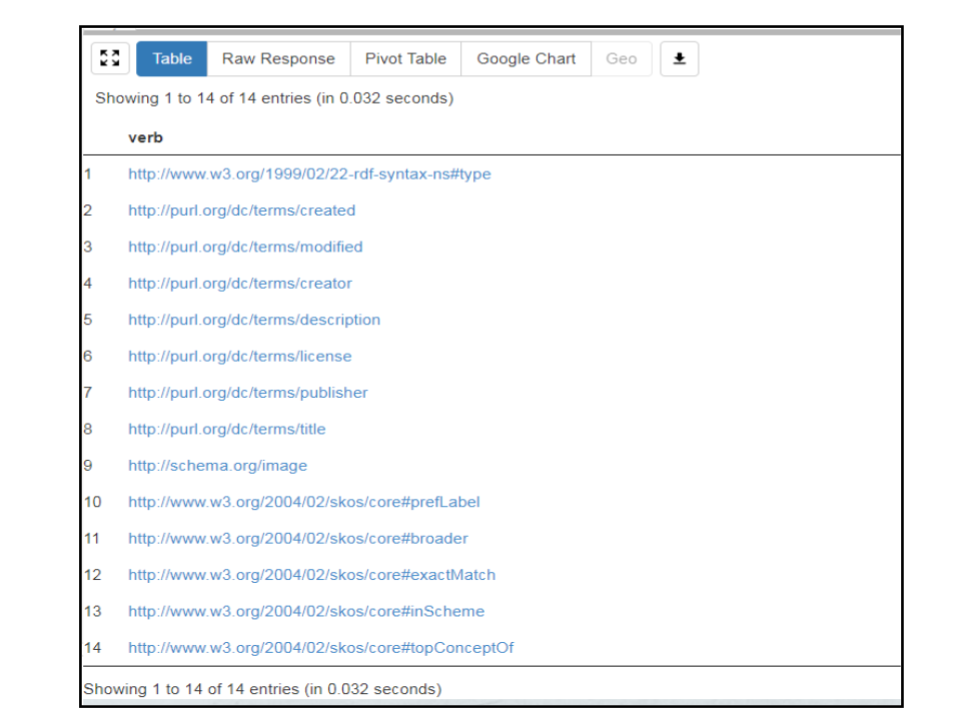
Cette simple requête SPARQL démontre l’intérêt de l’usage du langage SPARQL pour la valorisation du fonds documentaire ISTEX.
Un autre exemple illustrant la puissance de ce langage vous sera présenté dans un prochain billet.

Besoin d'aide ?
Consultez notre Faq, la documentation Istex ou nos tutoriels
N’hésitez pas à nous contacter si besoin, nous reviendrons rapidement vers vous !
Écrivez-nous

Erreur : Formulaire de contact non trouvé !